Creating a Powerful Course Search and Recommendation using Elasticsearch II
Contents
- 1 Introduction
- 2 Core Search Techniques We’ll Implement
- 2.1 Step 1: Setting Up the Search Endpoint
- 2.2 Step 2: Parse Inputs and Generate Embeddings
- 2.3 Step 3: Build the Elasticsearch Query
- 2.4 Step 4: _build_query(query, embedding, filters)
- 2.5 Step 5. _build_text_query(query)
- 2.6 Step 6.a. _build_vector_query(embedding)
- 2.7 Step 6.b. _build_vector_query_knn(embedding)
- 2.8 Step 7. _build_filters(filters)
- 2.9 Step 8. _build_highlight_config()
- 2.10 Step 9. _build_autocomplete_suggestions(query)
- 2.11 Step 10: _process_hits(hits)
- 2.12 Step 11: _process_suggestions(suggestions)
- 2.13 Step 12: _process_highlights(highlights)
- 2.14 Step 13: Define the URL
- 2.15 Step 14: Testing the Endpoint
- 3 Discussing Query Types
- 4 Course Recommendation with Synonyms (Optional)
- 5 Conclusion
Introduction
In this tutorial, we’ll build a comprehensive course recommendation and search engine using Elasticsearch, integrating multiple advanced search techniques. This engine will allow users to enter keywords and apply filters such as course level, category, language, and source to find the most relevant courses.
Core Search Techniques We’ll Implement
- Fuzzy Search – Handles “Pyton” → “Python”
- Vector Search – Finds conceptually similar courses
- Synonym Expansion – “JS” → “JavaScript”
- Smart Filtering – Level, language, category
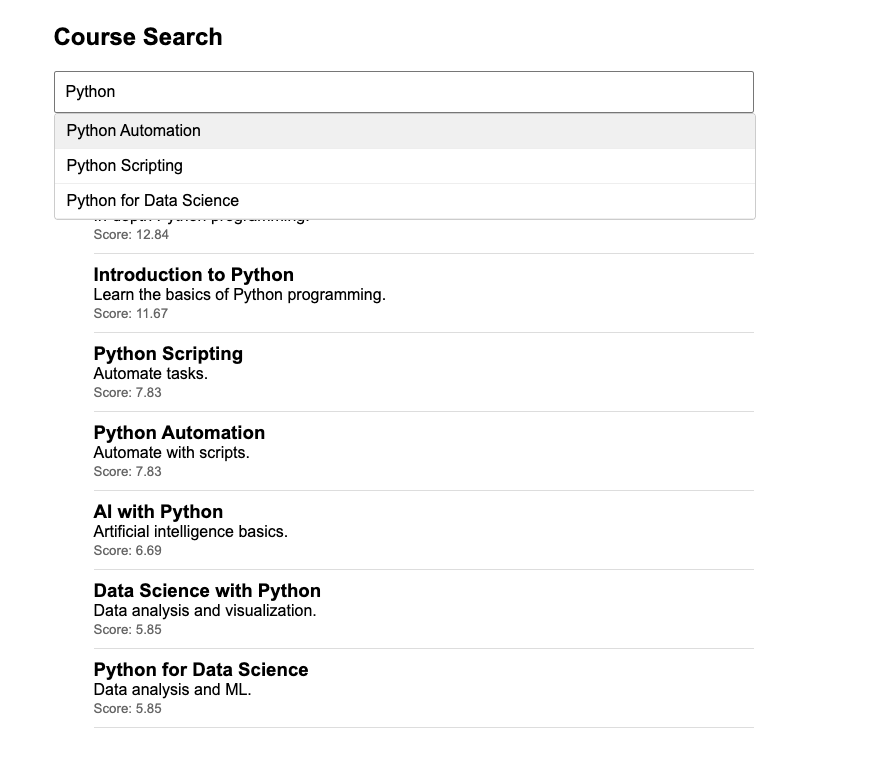
- Autocomplete / Prefix Search – Suggests course titles as users type (helps with quick search).
- Boosting / Relevance Scoring — Prioritises popular or highly rated courses.
For the project setup, please refer back to our previous tutorial where we covered the basics of configuring Elasticsearch with MySQL integration and setting up your development environment. Ensure the Elasticsearch cluster is running and the initial data indexing is complete before proceeding with this tutorial.
Step 1: Setting Up the Search Endpoint
In the example, we first load a pretrained sentence transformer model to generate vector embeddings for semantic search. This model converts the user’s text query into a numerical vector that captures meaning beyond keywords.
model = SentenceTransformer('paraphrase-MiniLM-L6-v2') # Lightweight model for embeddingsNext, we define and initialise the Elasticsearch client to connect to the local Elasticsearch server. The client is configured to retry failed requests up to three times and times out after 30 seconds to prevent hanging requests.
def get_elasticsearch_client():
"""Returns configured Elasticsearch client with connection pooling"""
return Elasticsearch(
['http://localhost:9200'],
max_retries=3,
retry_on_timeout=True,
request_timeout=30 # seconds
)
es = get_elasticsearch_client()Then, we define the search endpoint and use Django decorators for HTTP method enforcement, caching, and rate limiting to improve performance and security.
- The endpoint only accepts GET requests (
@require_GET). - Results are cached for 15 minutes to reduce repeated expensive searches (
@cache_page). - Rate limiting is applied to limit each IP to 100 requests per hour (
@ratelimit), protecting from abuse.
Step 2: Parse Inputs and Generate Embeddings
@require_GET
@cache_page(60 * 15) # Cache for 15 minutes
@ratelimit(key='ip', rate='100/h') # Prevent abuse
def course_search(request):
"""
Advanced course search endpoint supporting:
- Fuzzy search
- Vector-based semantic search
- Multi-field search with boosting
- Smart filtering
- Highlighting
- Autocomplete suggestions
"""
try:
# Parse and validate parameters
...
# Generate query embedding for semantic search
...
# Build complete search request
...
# Execute search with timeout
response = es.search(index='courses', body=search_body, request_timeout=10)
return JsonResponse({
'results': _process_hits(response['hits']),
'suggestions': _process_suggestions(response.get('suggest', {})),
'highlighted': _process_highlights(response.get('highlight', {})),
'took_ms': response['took']
})
except ElasticsearchException as e:
logger.error(f"Elasticsearch error: {str(e)}", exc_info=True)
return JsonResponse(
{'error': 'Search service unavailable'},
status=503
)
except Exception as e:
logger.critical(f"Unexpected error: {str(e)}", exc_info=True)
return JsonResponse(
{'error': 'Internal server error'},
status=500
)We extract the user’s query string (q) and optional filter parameters (level, category, etc.). Each filter corresponds to a course attribute we want to limit the search by:
query = request.GET.get('q', '').strip()
filters = {
'level': request.GET.get('level'),
'category': request.GET.get('category'),
'language': request.GET.get('lang'),
'source': request.GET.get('source')
}If a query exists, generate its semantic vector embedding using the SentenceTransformer model. This vector allows us to do similarity matching beyond simple keyword matching:
query_embedding = model.encode(query).tolist() if query else []To enable semantic search using vector embeddings, we must update our Elasticsearch index mapping to include a field for the dense vector. This field will store the numeric embedding vectors generated by the SentenceTransformer model.
For example, our index mapping for the courses index could look like this:
curl -X PUT "http://localhost:9200/courses_v2" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
...
"embedding": { "type": "dense_vector", "dims": 384 } // Adjust dims to match your model output size
}
}
}
'Make sure the dims value matches the output dimension of our embedding model (e.g., 384 for paraphrase-MiniLM-L6-v2).
Step 3: Build the Elasticsearch Query
Next, we prepare the search request body for Elasticsearch:
querycombines fuzzy text search + semantic vector search + filters.highlightconfigures snippets of matched text to be highlighted.suggestenables autocomplete suggestions for the input.sizelimits the number of results returned (pagination).
search_body = {
"query": _build_query(query, query_embedding, filters),
"highlight": _build_highlight_config(),
"suggest": _build_autocomplete_suggestions(query),
"size": 20 # Limit results for pagination
}Step 4: _build_query(query, embedding, filters)
Now, let’s construct the main Elasticsearch query combining text-based fuzzy search, vector similarity search (semantic), and filtering.
- Uses a
boolquery with two parts:- should: Contains two subqueries:
- Text fuzzy search on fields like course name, description, and instructor.
- Vector-based semantic search using embeddings.
- filter: Contains exact filters (like course level, category).
- should: Contains two subqueries:
minimum_should_match=1means at least one of theshouldqueries must match.
def _build_query(query, embedding, filters):
"""Constructs combined fuzzy + vector search query with filters"""
return {
"bool": {
"should": [ # Either match contributes to score
_build_text_query(query),
_build_vector_query(embedding)
],
"filter": _build_filters(filters),
"minimum_should_match": 1 # Require at least one should clause
}
}Step 5. _build_text_query(query)
Builds a fuzzy text search query over multiple fields with different importance weights.
- Uses Elasticsearch’s
multi_matchquery for matching the search term across multiple fields. - Field boosting:
"name^3": name field is weighted highest."description^2": description has moderate weight."instructor^1.5": instructor has a lower weight.
fuzziness: "AUTO"allows fuzzy matching for typos or similar words.- Uses a custom
"synonym_analyzer"to include synonyms in the search. (Refer to Course Recommendation with Synonyms (Optional)) "type": "most_fields"means it combines matching scores from all fields.
def _build_text_query(query):
"""Fuzzy search with field boosting and synonyms"""
return {
"multi_match": {
"query": query,
"fields": [
"name^3",
"description^2",
"instructor^1.5"
],
"fuzziness": "AUTO",
#"analyzer": "synonym_analyzer",
"type": "most_fields"
}
}Step 6.a. _build_vector_query(embedding)
We also add a semantic search based on vector similarity to the query.
- If embedding is empty (no query), returns a
match_noneto skip. - Uses
script_scoreto calculate the cosine similarity between the query vector and the stored document embedding. - The score is adjusted by adding 1.0 to ensure it’s positive (cosine similarity can be -1 to 1).
- This boosts documents that are semantically close to the query’s meaning, even if the words don’t exactly match.
def _build_vector_query(embedding):
"""Semantic search using precomputed embeddings"""
if not embedding:
return {"match_none": {}}
return {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": """
(cosineSimilarity(params.query_vector, 'embedding') + 1.0) * _score
""",
"params": {"query_vector": embedding}
}
}
}Note: If we want to prioritise exact cosine similarity score, we need to set index: false on our embedding field, store vectors, and use script_score.
Step 6.b. _build_vector_query_knn(embedding)
k-NN (k-Nearest Neighbors) search is a specialized Elasticsearch feature designed for efficient vector similarity search. Instead of calculating similarity scores manually with a script, it leverages optimized algorithms to directly find the top k nearest vectors to the query vector in the indexed documents.
def _build_vector_query(embedding):
"""Semantic search using k-NN"""
if not embedding:
return {"match_none": {}}
return {
"knn": {
"field": "embedding",
"query_vector": embedding,
"k": 20, # Number of nearest neighbors to return
"num_candidates": 100, # Number of candidates to consider for efficiency
"boost": 0.8 # Weighting factor to influence ranking score
}
}Note: If we want fast search at scale, keep index:true, similarity: cosine in mapping, and use knn queries (ANN). This is approximate but very efficient.
| Use Case | Mapping embedding | Search Type | Notes |
|---|---|---|---|
| Exact cosine similarity | "index": false | script_score | Slow, not scalable |
| Fast approximate search | "index": true, similarity: cosine | knn query | Fast, scalable, recommended for prod |
Step 7. _build_filters(filters)
Generates filter clauses to narrow down search results by exact matches, e.g. like level, category, language, etc.
- Loops over filter key-values.
- For any non-empty filter, it adds a
termfilter (exact match). - This restricts results strictly to the filter criteria.
def _build_filters(filters):
"""Construct filter clauses for valid filters"""
valid_filters = []
for field, value in filters.items():
if value:
valid_filters.append({"term": {field: value}})
return valid_filtersStep 8. _build_highlight_config()
Highlighting shows matched keywords in context on the frontend. Configures how Elasticsearch highlights matched parts of the results.
- Highlights matched snippets in:
name: returns the entire field (no fragments).description: returns a snippet fragment (max 150 chars).
- This helps UI show which parts of the text matched the search query.
def _build_highlight_config():
"""Configure highlighted snippets"""
return {
"fields": {
"name": {"number_of_fragments": 0},
"description": {
"fragment_size": 150,
"number_of_fragments": 1
}
}
}Step 9. _build_autocomplete_suggestions(query)
- Builds autocomplete suggestions based on prefix matching for the query.
- Only triggers if the query length is 3 or more characters.
- Uses Elasticsearch’s
completionsuggester on a special"title.suggest"field. - Supports fuzzy suggestions to tolerate typos.
- Skips duplicate suggestions.
def _build_autocomplete_suggestions(query):
"""Prefix-based suggestions for autocomplete"""
if not query or len(query) < 3:
return {}
return {
"course_suggestions": {
"prefix": query,
"completion": {
"field": "name.suggest",
"skip_duplicates": True,
"fuzzy": {"fuzziness": 1}
}
}
}Step 10: _process_hits(hits)
Transforms the raw Elasticsearch search hits into a clean, user-friendly JSON format.
- Extracts:
- Document ID (
_id) - Relevance score (
_score) - Source document fields (
_source)
- Document ID (
- Returns a list of dictionaries representing each search result.
def _process_hits(hits):
"""Extract and transform search results"""
return [{
'id': hit['_id'],
'score': hit['_score'],
**hit['_source']
} for hit in hits.get('hits', [])]
Step 11: _process_suggestions(suggestions)
Extracts the autocomplete suggestion texts from the Elasticsearch response.
def _process_suggestions(suggestions):
"""Extract autocomplete suggestions"""
return [
option['text'] for suggestion in suggestions.values()
for option in suggestion[0]['options']
]Step 12: _process_highlights(highlights)
Extracts highlighted snippets from the Elasticsearch response to show matched fragments.
- For each hit ID, it collects highlighted fragments per field.
- Only keeps the first fragment per field if there are multiple.
def _process_highlights(highlights):
"""Extract highlighted fragments"""
return {
hit_id: {
field: fragments[0] if fragments else None
for field, fragments in hit_highlights.items()
}
for hit_id, hit_highlights in highlights.items()
}Step 13: Define the URL
In the courses/urls.py, add the URL pattern for the search endpoint:
from django.urls import path
from . import views
urlpatterns = [
path('search/', views.course_search, name='course_search'),
]Then we need to include this urls.py in our main urls.py:
from django.urls import path, include
urlpatterns = [
# ... other routes
path('courses/', include('courses.urls')), # Adjust 'courses' to your app name
]Step 14: Testing the Endpoint
You can test the search functionality by visiting the following URL in your browser:
http://localhost:8000/courses/search/?q=java&level=beginner&category=programmingThis will send a request to the course_search view, which will query Elasticsearch and return JSON response containing search results, suggestions, highlights, and the elapsed time.
Discussing Query Types
- match Query:
- The match query analyses the input text and searches for documents containing the specified terms. It performs a full-text search with tokenisation and stemming.
- match_phrase Query:
- The match_phrase query searches for documents containing an exact phrase with terms in the specified order.
- Example: Best for search scenarios where the user might want to search for terms that start with a certain prefix, such as searching for
"coding tu"to match documents with"coding tutorial"or"coding tutor"
- match_all Query:
- The match_all query retrieves all documents in the index and is often combined with filters to refine results.
- Useful for debugging or when you want to display all courses under certain conditions.
- match_phrase_prefix Query:
- The match_phrase_prefix query performs a phrase search but allows the last term to be a prefix, enabling partial matches.
- Useful for autocomplete or when users type incomplete phrases, e.g., searching for “coding tu” matches “coding tutorial” or “coding tutor”.
- Multi-Match Query:
- The multi_match query allows searching across multiple fields with a single query, ideal for full-text search scenarios involving several fields.
- It supports different types, including:
- best_fields: (default) Returns the single best matching field’s score.
- most_fields: Matches as many fields as possible. Useful when the same term appears in multiple fields, increasing the relevance score. If “example search” appears in both
titleanddescription, the document gets a higher score because it matches multiple fields. phrase: Matches documents containing the exact phrase. The document must contain the exact phrase “example search” in thetitleordescriptionfields.cross_fields:Ideal for field normalisation scenarios where the search term is split across multiple fields. Consider a document with fields likefirst_nameandlast_name. If a user searches for"John Smith",cross_fieldsallows Elasticsearch to match “John” infirst_nameand “Smith” inlast_nameseamlesslyphrase_prefix: Performs a prefix search on the last term of the query, treating it as a phrase match. Imagine you have a product catalogue, and a user types “samsung gal”. You want Elasticsearch to match documents that start with “samsung gal”, such as “Samsung Galaxy S10” , or"Samsung Galaxy Note".
Summary of Match Query Types:
Here are the main types of match queries in Elasticsearch:
| Query Type | Description | Use Case |
|---|---|---|
match | Basic full-text search. | Fuzzy matching allows for minor spelling differences. |
match_phrase | Matches an exact phrase in the correct order. | When the order of words is important, like in titles or quotes. |
match_phrase_prefix | Phrase match with prefix matching on the last word. | Useful for autocomplete or search with prefixes. |
match_bool_prefix | Combines boolean logic with prefix matching. | Flexible searches that combine terms and allow for prefix matching. |
match_all | Matches all documents in the index. | For retrieving all documents, often used for testing. |
match with fuzziness | Fuzzy matching, allows for minor spelling differences. | To handle typographical errors or minor variations in terms. |
match with operator | Changes the default OR operator to AND for matching all terms. | To require all terms in the query to appear in documents. |
Course Recommendation with Synonyms (Optional)
Elasticsearch supports synonym mapping, which improves search results by treating related terms as equivalent. For example, we can configure “Java” as a synonym for “Spring Boot” or “HTML” as a synonym for “Web Development Basics.”
To implement this, we would typically maintain a list of synonyms, and when a user searches, the search query is expanded to include those synonyms, thereby increasing the likelihood of finding relevant results even if the exact term isn’t present in the content.
Step 1: Define Synonyms
Create a synonym file (e.g., synonyms.txt) to define related terms:
java, spring boot
web development basics, html, css, fundamentals
data science, machine learning, AIEach synonym group is separated by commas, and the words within a group are considered interchangeable for search purposes.
Step 2: Configure Elasticsearch Index with Synonym Analyser
When creating the index, configure a custom analyser that uses the synonym filter:
PUT /courses_v2_synonym
{
"settings": {
"analysis": {
"filter": {
"course_synonyms": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt",
"lenient": true, // Ignore malformed entries
"expand": false // For directional mappings
"updateable": true # Enable hot-reloading
}
},
"analyzer": {
"synonym_analyzer": {
"tokenizer": "standard", // tokenizer handles punctuation better
"filter": [
"lowercase",
"asciifolding", // Handle ñ → n, ç → c
"stemmer", // preserves root words
"course_synonyms"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "synonym_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"description": {
"type": "text",
"analyzer": "synonym_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"embedding": {
"type": "dense_vector",
"dims": 384,
"index": false
},
"category_id": { "type": "long" },
"sub_category_id": { "type": "long" },
"language": {
"type": "text",
"fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }
},
"source": {
"type": "text",
"fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }
},
"level": {
"type": "text",
"fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }
},
"instructor": {
"type": "text",
"fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }
},
"is_valid": { "type": "boolean" },
"modified_at": { "type": "date" },
"name_suggest": {
"type": "completion",
"analyzer": "simple",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50
}
}
}
}Make sure the synonyms.txt file is placed in the analysis directory of the Elasticsearch configuration folder, so it can be loaded properly.
If you already have documents in the original courses_v2, reindex them:
POST _reindex
{
"source": {
"index": "courses_v2"
},
"dest": {
"index": "courses_v2_synonym"
}
}Once configured, we generally do not need to change our existing search functions significantly, as the synonym filter is applied automatically during both indexing and searching.
Example of querying with synonyms:
GET courses_v2_synonym/_search
{
"query": {
"match": {
"description": "Spring Boot development"
}
}
}In this example, even though the user searched for “Spring Boot development”, the synonym filter will expand the query to also include “Java”, “JVM”, etc., and return any courses that contain these terms.
In more advanced cases, we can use NLP techniques or pre-trained models to automatically generate synonym lists based on user queries or text corpora. Tools like Word2Vec or GloVe can be used to generate word embeddings and find similar words, but these require more processing power and advanced infrastructure.
Conclusion
In this tutorial, we built a powerful and flexible course recommendation and search engine using Elasticsearch, integrating advanced search techniques like fuzzy matching, semantic vector search, synonym expansion, smart filtering, and autocomplete suggestions. By combining these approaches, we enhanced the relevance and user experience of the search functionality, allowing users to find courses more intuitively, even with typos or vague queries.
For the full source code, please visit the GitHub repository.
Share this content:
Leave a Comment